Материалы по тегу: big data
|
06.02.2025 [07:07], Владимир Мироненко
Российские компании увеличивают инвестиции в big dataРоссийский рынок big data демонстрирует устойчивый рост, о чём свидетельствует исследование K2 Cloud и Arenadata, в котором приняло участие более 200 руководителей ИТ-направлений крупных российских компаний. Согласно проведенному в рамках исследования опросу, почти треть (30 %) организаций крупного и среднего бизнеса планируют в 2025 году увеличить бюджеты на проекты, связанные с большими данными. Более 60% респондентов считают это стратегическим инвестированием, поскольку пока не научились оценивать эффективность таких инициатив, сообщается в исследовании. Более половины участников опроса планируют оптимизировать в 2025 году свои затраты на обработку больших данных с помощью облачных решений. 
Источник изображений: Arenadata/K2Cloud 57 % респондентов отметили, что запрос на внедрение решений big data исходит от бизнеса. 39 % всех участников оценивают текущие затраты компании на внедрение big data в сумму до 10 млн руб. — в основном на пилотные проекты. 15 % респондентов указали затраты от 10 до 50 млн руб. Это компании, которые находятся на этапе активного масштабирования своих big data-инициатив. 6 % респондентов сообщили о затратах от 50 млн руб. и выше. В данном случае речь идёт о крупных компаниях с большими финансовыми ресурсами. При этом 38 % респондентов могут оценивать влияние больших данных на рост бизнеса. 35 % опрошенных анализируют влияние работы с big data на сокращение затрат, 21 % — на рост выручки, 16% — на скорость изменений в компании. Около половины участников опроса при этом используют не менее двух подходов одновременно. 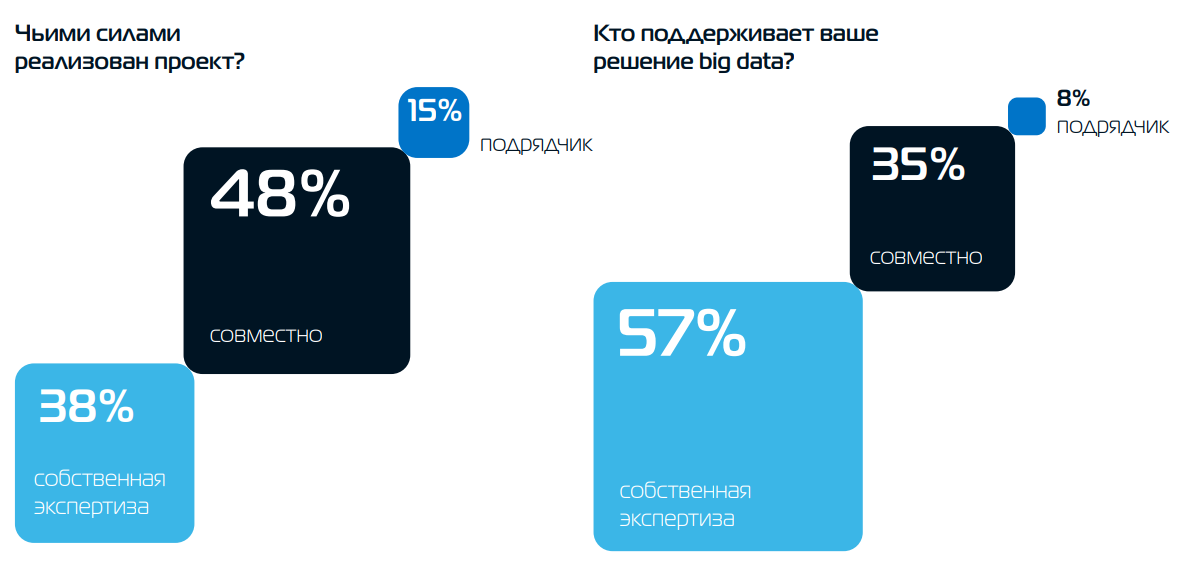 С изменением рынка и ростом объёмов данных компании стремятся использовать облачные решения для повышения эффективности работы с данными. 65 % опрошенных сообщили, что начнут в ближайшее время использовать облако для работы в этом направлении. В работе с big data 36 % компаний-респондентов внедряет отечественные решения, по 28 % выбрали зарубежные продукты и open source-решения. 40 % участников опроса сообщили об использовании комбинации разных решений. Большинство участников опроса ранее пользовались западными решениями on premise от Oracle, IBM, Vertica, Microsoft или облачными, например, Google BigQuery. Сейчас они переходят на решения отечественного вендора Arenadata либо на стек open source — PostgreSQL, Greenplum, Hadoop, ClickHouse, Kafka. Респонденты фиксируют улучшение качества российских решений для работы с big data и наличие успешных проектов на их основе, отметив, что для повышения их конкурентоспособности необходимо время и накопление успешных кейсов.  Основными вызовами при внедрении big data остаются нехватка квалифицированных кадров, необходимость изменения корпоративной культуры и отношения к данным, а также технические сложности. 4 из 5 респондентов отметили нехватку квалифицированных специалистов. Также важна позиция Chief Data Officer (CDO), который должен отстаивать интересы и защищать бюджет подразделения на уровне топ-менеджеров. В компаниях 83 % опрошенных выделенной роли CDO с соответствующими полномочиями и бюджетом пока нет. Несмотря на большой потенциал генеративного ИИ, 81 % респондентов пока не использует ИИ-инструменты для работы с big data, в основном из-за недостатка успешных кейсов и длительности обучения моделей. Вместе с тем интерес к аналитике существующих решений с помощью ИИ постепенно растёт, сообщается в исследовании.
03.02.2025 [15:06], Сергей Карасёв
Разработчик гипермасштабируемых аналитических хранилищ Ocient выбрал чипы AMD EPYC GenoaКомпания Ocient, специализирующаяся на разработке гипермасштабируемых аналитических хранилищ данных, объявила о заключении соглашения о сотрудничестве с AMD с целью повышения производительности, снижения затрат и максимизации эффективности ресурсоёмких вычислений и рабочих нагрузок ИИ. Ocient была основана в 2016 году. Компания предлагает платформу на основе реляционной базы данных с массовым параллелизмом, которая способна анализировать огромные объёмы информации (триллионы строк) за секунды или минуты. Хранилище Ocient Hyperscale Data Warehouse (OHDW) использует архитектуру Compute Adjacent Storage Architecture (CASA) для устранения узких мест в сетевой инфраструктуре и обеспечения максимально быстрого доступа к данным. Функция Zero Copy Reliability отвечает за высокую надёжность хранения информации без репликации с помощью кодирования с контролем чётности. 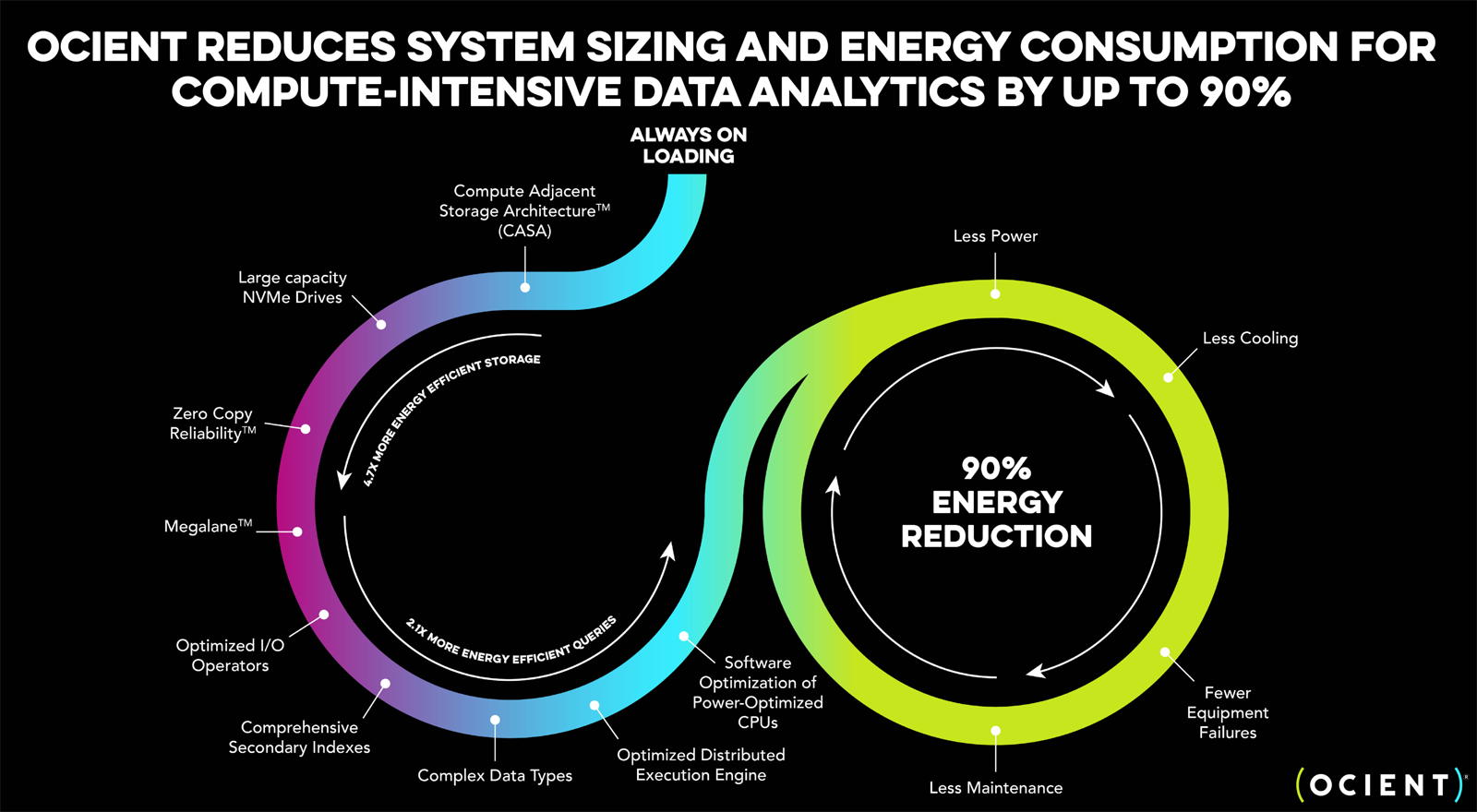
Источник изображения: Ocient Генеральный директор Ocient Крис Гладвин (Chris Gladwin) отмечает, что задачи ИИ и аналитики больших данных создают огромную вычислительную нагрузку на ЦОД по всему миру. Это означает, что повышение эффективности оборудования и программного обеспечения имеет решающее значение для снижения расходов, уменьшения энергопотребления и улучшения производительности. В этой связи Ocient сделала выбор в пользу процессоров AMD EPYC 9654 поколения Genoa с 96 вычислительными ядрами, которые придут на смену 28-ядерным чипам Intel Xeon Gold 6348 семейства Ice Lake-SP. Говорится, что благодаря более высокой плотности ядер изделия AMD обеспечат трёхкратный рост производительности для ресурсоёмких вычислительных задач. При этом снизятся эксплуатационные расходы, что обусловлено повышением быстродействия и энергоэффективности. Плюс к этому достигается гибкость масштабирования.
18.12.2024 [16:00], Владимир Мироненко
МТС выделит облачные сервисы, ИИ-технологии и большие данные в самостоятельную компаниюМТС проводит реструктуризацию, в рамках которой ключевые активы будут выведены в самостоятельную структуру — компанию MWS (MTС Web Services, АО МВС), зарегистрированную в 2021 году в Москве в составе группы компаний МТС, сообщил «Коммерсантъ» со ссылкой на информированные источники. В настоящее время в АО МВС входит облачный бизнес группы с 15 ЦОД. Как сообщает собеседник «Коммерсанта», в рамках реструктуризации в MWS также войдут команды, занимающиеся разработкой технологий ИИ, Big Data и облаками. В частности, в отдельную компанию могут войти «МТС Диджитал», МТС AI, MWS (бывший МТС Cloud), Big Data, а также могут быть добавлены активы в области инноваций и кибербезопасности. Руководство новой структурой могут доверить первому вице-президенту МТС по технологиям Павлу Воронину. Как ожидается, к 2030 году выручка компании составит 230 млрд руб. О планах перевести в дочернее предприятие MWS ещё ряд активов МТС объявила этой весной. 
Источник изображения: MWS По словам другого источника «Коммерсанта», в компанию могут также войти подразделение по кибербезопасности и VisionLabs (системы умного зрения). При этом внутри самих IT-активов компании изменений не будет. Источник утверждает, что МТС в дальнейшем может провести IPO MWS, хотя конкретные сроки он не указывает. Эксперты назвали частой практикой для рынка, когда под IPO выделяется актив, потенциально оцениваемый с более высокими мультипликаторами. Вывод дочерних структур на IPO также позволяет снизить долговую нагрузку на компанию и привлечь инвестиции. В сентябре президент МТС Вячеслав Николаев сообщил в интервью Forbes, что выведет на IPO до пяти компаний в ближайшие несколько лет, назвав одним из первых направление рекламных технологий МТС Ads.
27.11.2024 [19:42], Руслан Авдеев
Интернет-квартирография: «Телеком Радар» от VK позволит провайдерам оценить качество услуг связиVK обеспечила бизнес-клиентов новым инструментарием. Сервис «Телеком Радар» для телеком-операторов позволяет анализировать качество связи и принимать решения о модернизации инфраструктуры. Пресс-служба компании сообщает, что им смогут воспользоваться операторы широкополосного доступа в Сеть. Так, клиенты получат возможность оценить долю на рынке кабельного интернета в том или ином регионе и, основываясь на полученной статистике, сравнивать уровень своих сервисов с показателями конкурентов, искать проблемы со связью и обеспечивать рост качества услуг для своих клиентов. «Телеком Радар» находится в ведении VK Predict — его используют и крупнейшие операторы мобильной связи для анализа качества соединения в привязке к конкретным локациям. Показатели можно сравнивать с данными конкурентов или определять долю рынка в том или ином регионе. Как сообщают в компании, анализ качества связи основан в первую очередь на параметрах потребления видео, который является не только популярным, но и одним из самых «тяжёлых» видов контента, требующего устойчивого широкополосного соединения. «Телеком Радар» позволяет оценить пользовательский опыт, реальное покрытие сети на местах, а также получить данные, которые помогут оценить необходимость модернизации инфраструктуры. В частности, это позволит сохранить лояльность абонентов и избежать их оттока. 
Источник изображения: VK Predict Как сообщают в VK Predict, точность геопозиционирования «Телеком Радара» даёт возможность определять, в каких населённых пунктах с покрытием не всё благополучно, проверять состояние инфраструктуры, а также спланировать её обновление и оценить итоговый результат. Операторы кабельной инфраструктуры могут распознавать проблемы со связью, например, в многоквартирных домах, в том числе в случае перегрузки сети одним пользователем. Также можно оценить изменение числа абонентов и эффект маркетинговых кампаний, перспективы расширения инфраструктуры по новым адресам и другие параметры. Сервис, как утверждают в компании, оценивает реальный опыт взаимодействия пользователей с продуктами группы VK, в том числе метрики просмотров видео на площадках ВКонтакте и VK Видео. Клиенты получают аналитику на основе агрегированных обезличенных данных. Для аналитики используются как классические программные инструменты, так и ИИ-алгоритмы. В числе ключевых решений не только «Телеком Радар», но и «ГеоКурсор» для анализа разных локаций, а также «Девелопер» для «оптимальной квартирографии» в жилых комплексах. Наконец, Predict AutoML предназначен для конструирования решений на основе алгоритмов машинного обучения без привлечения опытных IT-специалистов. В VK Predict предлагаются и другие бизнес-сервисы.
01.10.2024 [21:45], Владимир Мироненко
«Группа Аренадата» привлекла 2,7 млрд рублей в ходе IPOПАО «Группа Аренадата» (Группа Arenadata), российский разработчик ПО для систем управления и обработки данных, объявило об успешном проведении первичного публичного предложения (IPO), прошедшего по верхней границе ценового диапазона. Сообщается, что «Группа Аренадата» стала первой публичной компанией среди разработчиков системного ПО для работы с данными. Стоимость акции составила 95 руб., а оценка рыночной капитализации компании достигла 19 млрд руб. В ходе IPO со стороны текущих акционеров было предложено 28 млн акций на сумму около 2,7 млрд руб. по цене IPO, включая 2,8 млн акций, которые могут быть использованы для стабилизации цены акций на вторичных торгах в период до 30 дней после начала торгов. В результате IPO акционерами группы стали около 30 тыс. частных инвесторов. Акции были распределены между категориями инвесторов в следующей пропорции: 57 % получили институциональные инвесторы, 27 % — розничные инвесторы и 16 % — партнёры продающих акционеров. Аллокация (распределение акций) розничным инвесторам составила около 5 %. Каждый розничный инвестор получил не менее 1 акции, те, кто подал более 10 заявок, не получили аллокации. 
Источник изображения: «Группа Аренадата» Как отметил в интервью «Агентству Бизнес Новостей» представитель ПАО «Группа Аренадата», на размер аллокации повлиял «размер сделки, повышенный интерес как со стороны институциональных инвесторов — крупнейших УК, инвестиционных фондов, так и со стороны частных инвесторов». По данным «Агентства Бизнес Новостей», в ходе IPO Iva Technologies аллокация среди розничных инвесторов составила 5–10 %, столько же у IT-компании Positive Technologies и 4 % — у «Группы Астра». После выхода на биржу доля акций в свободном обращении (free-float) составит порядка 14 % от акционерного капитал группы. Акции под тикером DATA и ISIN RU000A108ZR8 были включены во второй уровень листинга Московской биржи. Первые торги акциями «Группы Аренадата» прошли сегодня, 1 октября 2024 года. Компания была основана в 2015 году как дочерняя структура IBS, но впоследствии отделилась от родительской компании. В 2017 года компания представила свой первый продукт — Arenadata Hadoop. В дальнейшем на рынок были выведены Arenadata DB, Arenadata QuickMarts, Arenadata Cluster Manager, Arenadata Streaming, Arenadata Postgres и т.д. По состоянию на 2023 году объём данных на платформе Arenadata превысил 60 Пбайт.
24.09.2024 [14:45], Андрей Крупин
VK создала собственную платформу для работы с большими объёмами данных и машинным обучениемЗанимающаяся разработкой корпоративного ПО компания VK Tech (входит в экосистему VK) сообщила о запуске Data Platform — платформы для комплексной работы с большими объёмами данных, нейросетями и искусственным интеллектом. В течение трёх лет в VK намерены инвестировать в новое решение и связанные с ним сервисы до 4 млрд руб. VK Data Platform относится к категории универсальных инструментов Enterprise Data Platform (EDP) и позволяет решать широкий спектр задач: от хранения и обработки данных до выполнения аналитических процессов и разработки моделей машинного обучения. В основу платформы положены собственные разработки компании, в частности, Tarantool и S3-совместимое хранилище Cloud Storage, и доработанные VK технологии, среди которых Trino, PostgreSQL, Airflow и многие другие. 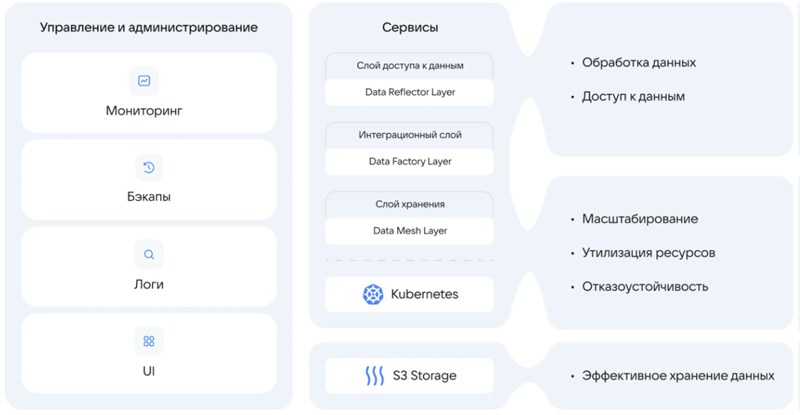
Функциональная архитектура VK Data Platform Компоненты VK Data Platform разворачиваются на основе Kubernetes. Это позволяет динамически распределять вычислительные мощности, эффективно утилизировать аппаратное обеспечение и предоставлять высокий уровень отказоустойчивости. Пользователям доступны централизованные инструменты мониторинга, создания резервных копий данных и графический интерфейс для управления платформой. Платформа может быть развёрнута на различных типах инфраструктуры, включая публичные и частные облака, а также собственные серверы заказчика. В ней предусмотрены типовые архитектуры на основе Data WareHouse, Data Lake, LakeHouse и Data Mesh, MLOps-конвейеров, а также конфигурации для систем с высокой транзакционной нагрузкой. По заверениям разработчика, это позволяет быстро адаптировать её под задачи любой компании и ускоряет интеграцию решения в корпоративный IT-ландшафт. |
|

